
Cloud data warehouse adoption continues to increase exponentially amongst organizations big and small. However, for most organizations, data housed in warehouses is inaccessible to data stakeholders from business teams, such as marketers and product managers. This is because gathering data inside the data warehouse typically requires the technical expertise of data engineers and data analysts.
Enable self-service analytics using your warehouse data
Today, we’re excited to announce the release of Self-Service Setup for Data Warehouse Sources, simplifying the process for data teams to get data into Indicative and enabling marketing and product management teams to get started with analysis and exploration. With Indicative data synced with your warehouse data, non-technical users can create their own funnel charts, journey analysis, and other types of visualization without requiring knowledge of SQL. Not only does this free resourcing bottlenecks for your data team, but by empowering your business teams with faster answers to their questions you’ll also be able to adapt and respond to user engagement in real time.
Previously, importing data from your warehouse into Indicative required the assistance of an Indicative Solutions Engineer to prepare your data and complete the final step. Now, using a self-guided workflow, teams can complete the end-to-end workflow to load event data from their warehouse to Indicative on their own!
With this release, users can use a step-by-step UI to:
- Schedule, model, and load their data
- Run validation to determine if their data is modeled appropriately for analytics within Indicative
- Review a summary of what data will be loaded
- Exclude unnecessary events and properties with a few clicks
Our first release will support BigQuery as a source, using the standard Snowplow or Firebase schema, or your own custom schema.
Note: Data Warehouse integrations are currently only available to customers on Indicative’s Enterprise Pricing Plan. If you’re a Standard or Growth customer and interested to try out this feature, please reach out to your customer success manager.
Try it out
Ready to get started?
Simply log into your Indicative instance, Navigate to “New Data Source”, and select “Connect Via Data Warehouse or Lake”. Choose BigQuery as your source and pick a schema (Snowplow, Firebase, or Define your Own).
You’ll need administrative access to your BigQuery console in order to obtain the GCP Project ID, Dataset Name, and Table Name that contains the data you wish to import. Follow along the instructions in the self-guided workflow to create an Indicative Service Account and grant Indicative read-only access to your dataset.
Once the Service Account is properly set up to read your BigQuery dataset, you’ll be guided to model your event and user data so that event names, timestamps, and identities are properly mapped from your warehouse to Indicative. By default, Indicative will import all events and associated event properties. After the initial setup workflow is completed, you can choose to apply filters and exclusions in your Data Source settings.

Along the way, the self-service setup workflow will perform a couple of sanity checks on your data with the model that you provided. This includes checking for:
- Valid event and timestamp fields (Do at least 80% of your records have this value populated?)
- Total number of unique events. We recommend 20-300 unique events and limit it to 2000.
- Valid identities for users (Does the distribution of authenticated and unauthenticated users look right?)
The final step is to configure a recurring schedule interval to check for any new data to import into Indicative. We use the Load Timestamp Field to determine when an event is published.
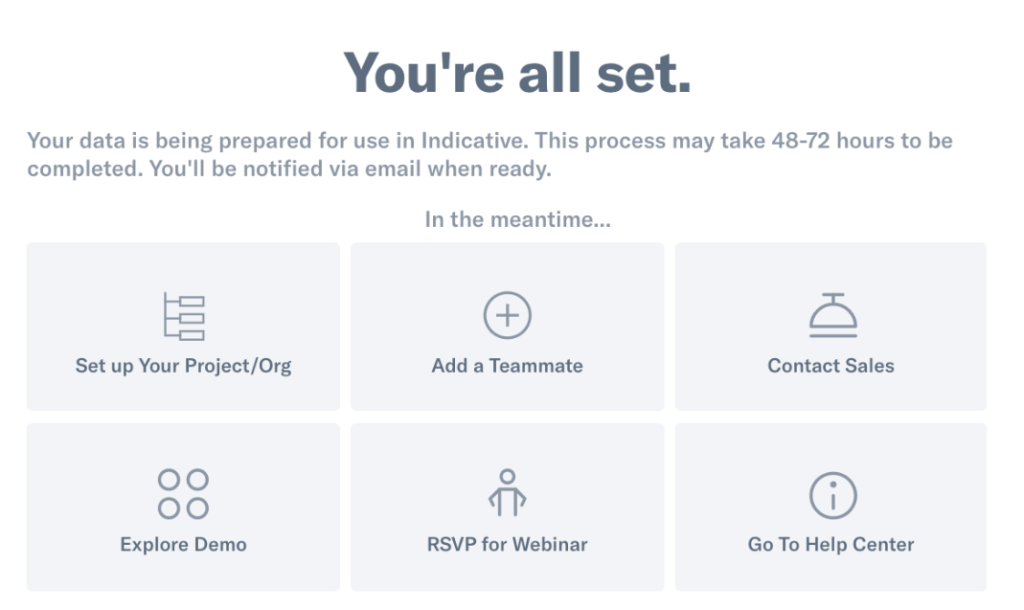
And Voilà, that’s it, you’re done! Depending on the size of your dataset, the import can finish in just a couple of hours. Larger event volumes will take up to 48-72 hours.
Looking for more detailed step-by-step instructions? Please refer to our support documentation in the links below, based on the schema you use.
Additional Data Warehouse sources coming soon!
Looking to use the same workflow to import data from another warehouse source? No problem, we’ve got you covered. In the upcoming months, we plan to enable self-service setup for Snowflake and Amazon Redshift. You can subscribe to our monthly customer newsletter or follow our monthly product update blog series to stay up-to-date on new feature releases. In the meantime, if you want to connect these sources, please complete the steps in the existing setup flow in the Indicative UI, which will still require the assistance of our Solutions Engineering team.
If you’re new to Indicative altogether and want to see how easy it is to get started with exploring your data, you can try out our interactive demo or sign-up for a free trial account.


